
by Andrea Di Stefano | Feb 15, 2021 | artificial intelligence/machine learning
Three Essential Rules to Achieve a Great ROI with AI Think of AI implementation as investing in an expensive, high-performance oven for your restaurant. As cool as it may be, an oven is basically just a tool. To offer great cuisine, you still need good-quality...

by Andrea Di Stefano | Dec 30, 2020 | artificial intelligence/machine learning
The 4 Types of Data Analytics to Enhance your Business According to Sherlock Holmes: “It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.” Thanks, Sherlock! We took your...
by Andrea Di Stefano | Dec 28, 2020 | artificial intelligence/machine learning
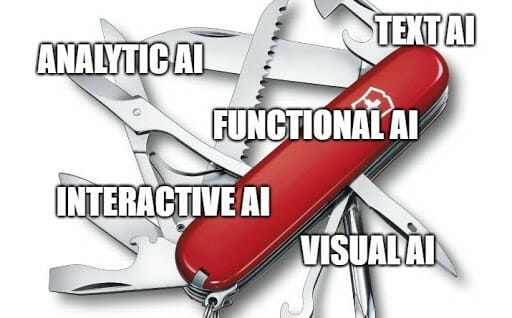
The 5 Main Types of AI your Business Can Benefit from Artificial intelligence is like a Swiss Army knife: a single tool that can be used in a myriad of different ways. We can broadly group the fields of application of AI into 5 main macro-areas: Text AI Visual AI...

by Andrea Di Stefano | Dec 21, 2020 | artificial intelligence/machine learning
How to Make Waste Management and Recycling Smarter with AI Poor WALL-E. It must have seen too few bras in its long robotic life to properly sort them from other waste. So… how can we teach it and all the other robots to better separate trash? And how can we improve...

by Andrea Di Stefano | Dec 7, 2020 | artificial intelligence/machine learning
How to Improve Call Centers with AI and Machine Learning Apparently, we can’t help Barbara anymore. But how can we avoid the premature aging of Megan, John, Anthony, and all of their hard-working colleagues in traditional call centers? And how to improve the...

by Andrea Di Stefano | Dec 4, 2020 | artificial intelligence/machine learning
How AI Can Help Power Utilities Meet Modern Challenges In recent years, electric utilities have faced numerous issues. Above all, increasingly complex and less regulated markets, energy diversification, and growing competition. How to deal with these challenges? Well,...